Here disclosed is a novel compression technique I call Deep Learning Semantic Vector Quantization (DLSVC) that achieves in this sample 9,039:1 compression! Compare this to JPEG at about 10:1 or even HEIC at about 20:1, and the absolutely incredible power of DL image compression becomes apparent.
Before I disclose the technique to achieve this absolutely stunning result, we need to understand a bit about the psychovisual mechanisms that are being exploited. A good starting point is thinking about:
It was a dark and stormy night and all through the house not a creature was stirring, not even a mouse.
I’m sure each person reading this develops an internal model, likely some combination of a snug, warm indoor Christmas scene while outside a storm raged, or something to that effect derived from the shared cultural semantic representation: a scene with a great deal of detail and complexity, despite the very short text string. The underlying mechanism is a sort of vector quantization where the text represents a series of vectors that semantically reference complex culturally shared elements that form a type of codebook.
If a person skilled at drawing were to attempt to represent this coded reference visually, it is likely the result would be recognizable to others as a representation of the text; that is, the text is an extremely compact symbolic representation of an image.

Created by DALL·E mini developed by Boris Dayma et al. 2021-2022
So now lets try a little AI assisted vector quantization of images. We can start with the a generic image from Wikipedia:
{kind=link}

A cat sitting on a bench, Varna, December, 2018 (https://commons.wikimedia.org/wiki/File:A_feral_cat_sitting_on_a_bench,_Varna,_December,_2018.jpg)
Next we use AI to reduce the image to a symbolic semantic representation. There are far more powerful AI systems available, but we’ll use one that allows normal people to play with it, @milhidaka’s caption generator on github:
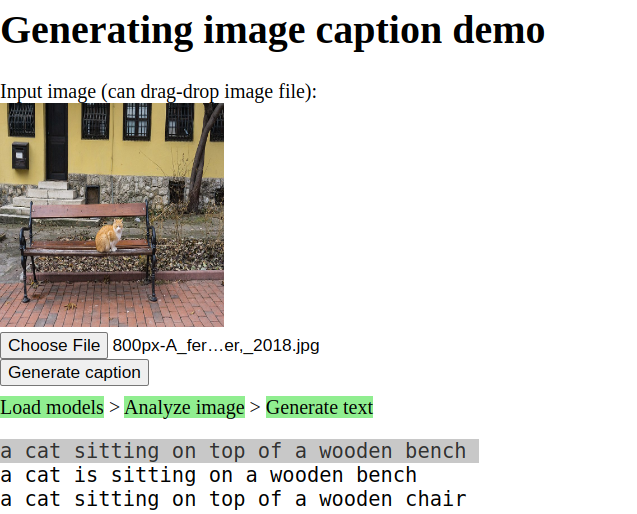
This is a cat sitting on top of a wooden bench which we can LZW compress assuming 26 character text to a mere 174 bits or 804D22134C834638D4CE3CE14058E38310D071087. That’s a pretty compact representation of an image! The model has been trained to understand a correlation between widely shared semantic symbols and elements of images and can reduce an image to a human-comprehensible, compact textual representation, effectively a lossy coding scheme referencing a massive shared codebook with complex grammatical rules that further increase the information density of the text.
Decoding those 174 bits back to the original text, we can feed them into an image generating generative AI model, like DALL·E mini and we get our original image back by reversing the process leveraging a different semantic model, but one also trained to the same human language.
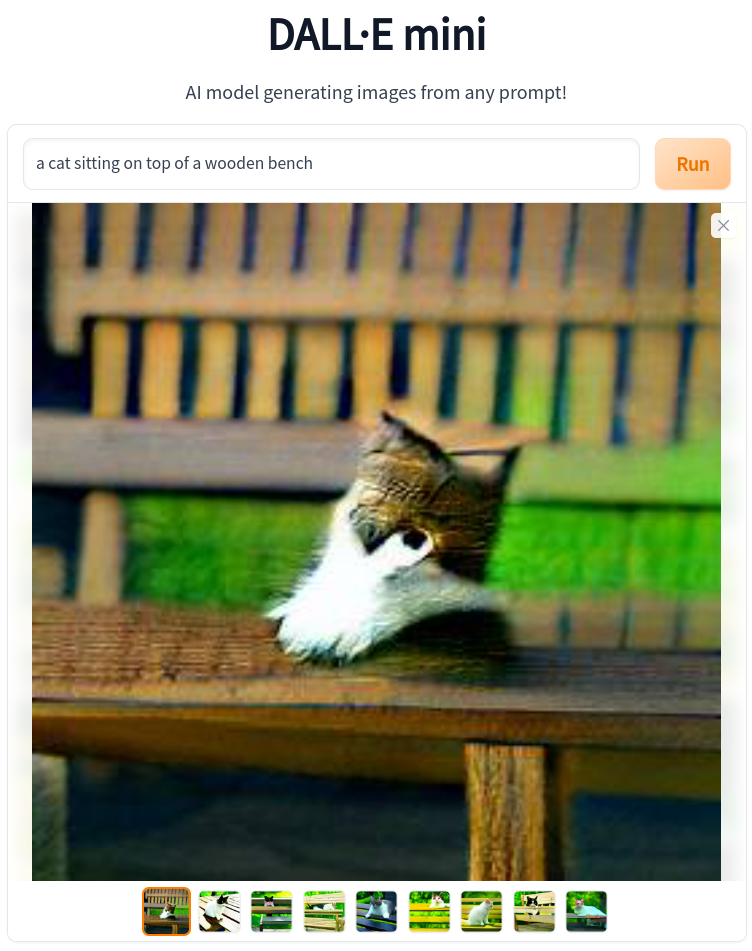
It is clearly a lossy conversion, but here’s the thing: so too is human memory lossy. If you saw the original scene and 20 years later, someone said, “hey, remember that time we saw the cat sitting on a wooden bench in Varna, look, here’s a picture of it!” and showed you this picture, I mean aside from the funny looking cat like blob, you’d say “oh, yeah, cool, that was a cute cat.”
Using the DALL·E mini output as the basis for computing compression rather than the input image which could be arbitrarily large, we have 256×256×8×3 bits output = 1,572,864 bits to represent the output image raw.
WebP “low quality” compressing the 256×256 image yields a file of 146,080 bits or 10.77:1 compression.
My technique yields a compressed representation of 174 bits or 9,039:1 compression. DALL·E 2‘s 1024×1024 output size should yield 144,624:1 compression.

DALL·E 2023-01-22 02.07.41 – a cat sitting on top of a wooden bench
This is not a photograph. This is Dall-E 2’s 25,165,824 bit (raw) interpretation of the 174 bit text “a cat sitting on top of a wooden bench” which was derived by a different AI from the original image.
So just for comparison, lets consider how much we can compress the original image, resizing to 32×21 pixels and, say, webp, to 580 bytes.
 Even being generous and using the original file’s 7,111,400 bytes such that this blancmange of an image represents 12,261:1 compression, it is still 12× worse compression than our novel technique, it is hard to argue that this is a better representation of the original image than our AI-based semantic codebook compression achieved.
Even being generous and using the original file’s 7,111,400 bytes such that this blancmange of an image represents 12,261:1 compression, it is still 12× worse compression than our novel technique, it is hard to argue that this is a better representation of the original image than our AI-based semantic codebook compression achieved.
Pied Piper got nothin’ on this!
An aside: the introduction of semantic description to image generation that largely follows human expectations, much as LLM-style AI similarly follows human expectations, can be considered a sort of Braitenberg Vehicle, we know LLMs are predictable, replicable, deterministic. As Braitenburg posits in his book Vehiciles, Experiments in Synthetic Psychology, AI is an experiment in synthetic psychology.
It is not absurd to posit that the compression model proposed in this little post is a good analog to human memory. Human brains are finite, error prone blobs of mush. Humans tend to be confident in their memories, memories recalled and described as language. Memory may very well be a process very similar, perhaps almost exactly identical, to the process proposed here: image is fed into a convolutional neural network (CNN) which assigns semantic tokens, tokens with shared “cultural” meaning to describe the image. Those tokens, not the image are stored. On recall the tokens are fed into a generative adversarial network (GAN) which constructs an image that by combining dictionary and cultural assumptions creates an image matching the description.
When a human is shown a true reproduction of a remembered scene, it will generally trigger recognition, often not immediately. It seems likely a process of reduction to semantic tokens and then token pattern matching, or something allegorically similar. It may also be sort of the reverse, the current image is stored literally, an allegorical raster, and an allegorical GAN converts stored semantic clusters into test images for comparison.
When people reject a true and literal reproduction of an old memory as not matching, either the tokens have been lost or the token meaning has changed for the user such that the image generated by, say, “bench” is unrecognizable from the image to which that token was assigned at the time of memory formation.
Given that evolution tends to drive energy and matter use efficiency to optimize survival, brains would be unlikely to store raw representations or mechanisms of webp-like allegorical tradeoffs between image fidelity and compression, rather they would take advantage of the vastly superior compression and reconstruction offered by shared semantic codebook compression.

[…] future by pattern matching against history, something human cognition does to reduce reality into space saving symbolic representation which leads us to see cyclic patterns in everything, even random noise. We also tend to allude to […]