David Gessel
Manually Update Time Zone Data on Android 10
One of the updates that stops when your carrier decides you have to buy a new phone to keep their profits up is the time zone data, which means as regions decide they will or won’t continue using standard time and will switch permanently to lazy people time (or not), time zone calculations start to fail, which can be awfully annoying when it causes you to miss flights or meetings. It is probably something you’ll want to keep up to date. Unfortunately, this requires root access to your phone because… profits depend on the velocity by which first world money is converted to e-waste to poison third world children. Yay.
Root requires reflashing your device, which means wiping all your data and apps and reinstalling them, so easier to do on a new phone than backing up and restoring and re-configuring all your apps. Sooner or later your vendor will stop supporting your device in an attempt to get you to throw it away and buy a new one and you’ll have to root it to keep it up to date and secure so you might as well do it now, void their stupid warranty, and take control of your device.
You should also take a moment to write your elected representatives and demand that they take civil action against this crap. Lets take a short rant break, shall we?
Planned obsolescence, death by security flaws, and vendor locks should be prosecuted, not just as illegal profiteering but as environmental crimes for needlessly flooding the world with e-waste. If you own a device you have the right to use it as you like and any entity that by omission or obfuscation of reasonable information needed to keep that device operational is depriving legitimate owners of rightful value. Willfully obstructing security updates, knowing full well the risks implied, is coercive if not extortion. Actively blocking the provision of third party services intended to mitigate these harms through barratry and legal extortion should be prosecuted aggressively. Everyone who has purchased a phone that has been intentionally and unfairly life-limited by non-replaceable batteries, intimidation of repair services, manipulation of the spare parts market, or restrictions or obfuscation of security updates is due refund of the value thus denied plus penalties.
Ah, that feels better, no?
Assuming you have a rooted phone, adb installed on your computer, and your TZ data is out of date, lets get it fixed, shall we? The problem is that TZ data comes from IANA, from here actually, and is versioned in a form like 2023c, the current as of now. That’s lovely but the format they provide is not compatible with android and needs to be transformed. Google seems to have some tools for this in the FOSS branch of Android, but it seems a little useless without a virtual environment, a PITA. But the good folks at LineageOS (yay, FOSS!!!) maintain their version of the tool with the thus created output data in their git, which we can use for all android devices (it seems). The files we need are in this directory: note that these are 2023a, but 2023c is identical to 2023a, reverting some changes made in 2023b because, I don’t know, the whole mess about getting up an hour earlier or later being some traumatic experience when it happens twice a year is catastrophic for people’s sense of well being, but when they get up at different times on days off than on work days, that doesn’t count or something. OMG. so drama. people. sometimes it hurts to be associated with them as a species. Not that I care, but stop messing around and just pick one. So many rant triggers in this whole mess.
Anyway, proceeding with the assumption your device is rooted and you have adb installed on your computer, the files needed are:
tzdata a binary file that if you view with a text editor should start with: tzdata2023a tzlookup.xml an xml file that should (nearly) start with: <timezones ianaversion="2023a"> tz_version a simple text file that should have one line: 003.001|2023a|001
Download the compressed .tgz archive of the output_data directory from here by clicking on the [tgz] text at the top right
You should get a .tgz archive, from which you want to extract:
tzlookup.xmlfrom theandroidfoldertzdatafrom theianafoldertz_versionfrom theversionfolder
Here’s the tricky bit, you gotta get these files to the right places. So I mounted my android on my computer and created a folder TZData in Downloads and copied the files there, this resolved to /data/media/0/Download/TZdata/ on my device. While you’re there, make a folder like oldTZ in the same place for backup. Everything else is done by command line via adb.
(comments are demarked with "#", the prompt is assumed) # get shell on your device adb shell # get root, if this fails, you don't have root, bummer, you don't really own your device. su root # verify your tz data is where mine was, if so copypasta should be safe. find / -name tzdata 2>/dev/null #output for me looks like some are symlinks /apex/com.android.tzdata/etc/tz/tzdata /apex/com.android.tzdata@290000000/etc/tz/tzdata /apex/com.android.runtime/etc/tz/tzdata /apex/com.android.runtime@1/etc/tz/tzdata /system/apex/com.android.runtime.release/etc/tz/tzdata /system/apex/com.android.tzdata/etc/tz/tzdata /system/usr/share/zoneinfo/tzdata # did ya get the same or close enough to figure out what to do next? good. # Backup your old stuff cp /system/apex/com.android.tzdata/etc/tz/* /data/media/0/Download/oldTZ # your directories are read only, so you need to fix that, scary but reversible mount -o rw,remount / mount -o rw,remount /apex/com.android.tzdata mount -o rw,remount /apex/com.android.runtime # copy the new files over the old files, the last location is legacy and doesn't # seem to have a copy of tzlookup.xml, so we don't put a new one there, but check ls /system/usr/share/zoneinfo # only tzdata and tz_version? Good. cp /data/media/0/Download/TZdata/* /apex/com.android.tzdata/etc/tz cp /data/media/0/Download/TZdata/* /apex/com.android.runtime/etc/tz cp /data/media/0/Download/TZdata/* /system/apex/com.android.tzdata/etc/tz cp /data/media/0/Download/TZdata/tz_version /system/usr/share/zoneinfo cp /data/media/0/Download/TZdata/tzdata /system/usr/share/zoneinfo # all done, now we just gotta read-only those directories again mount -o ro,remount / mount -o ro,remount /apex/com.android.tzdata mount -o ro,remount /apex/com.android.runtime # and why not reboot from the command line? reboot
That was fairly painless once you know what to do and have root, no? it worked for me, my phone rebooted and the time zone database appears to be updated. YMMV, hopefully not the reboot successfully part but bricking a phone is a risk because, you know, profits. After that tz file surgery I created a new event in a US time zone that recently changed their daylight savings to pacify the crazies and it seemed to work as expected.
Autodictating to self using Whisper to preserve privacy
Whisper is a very nice bit of code released by OpenAI, the kind people who brought us ChatGPT. It’s a speech to text tool that can handle a huge array of languages and runs locally, as in on your hardware with your data. There’s an API you can use on their servers, but only if you are sure the audio files and text can be released to the public. Never put any data on anyone else’s hardware that you wouldn’t want to have leaked on pastebin or published in the New York Times; that goes for all services including gmail, Outlook, Office 365, etc. Never, ever use someone else’s hardware to store proprietary or sensitive data. It’s just mind-bogglingly stupid, and yet so many people fail to comprehend that “in the cloud” just means “on someone else’s computer.”
This is also true for most speech-to-text tools that (seemingly) kindly offer to translate your ramblings to text out of the goodness of the developer’s hearts. Lots of people use this feature on their phones without realizing that, like Alexa, any voice command tool is an audio monitoring device you stupidly paid for and installed yourself on behalf of corporate spies who are all too happy to listen to whatever you have to say. If you have an Alexa, get a hammer right now and smash it. Go on, I’ll wait. Good job. Privacy restored. Oh, smart TV too? Unplug that stupid thing from the internet. Same for all your “smart” devices. You thought “smart” meant you were smart for buying it? Noooo… you’re a moron for buying it, the company was smart for convincing you to install monitoring devices in your house at your own expense. Congrats. Own goal. When you’re finished destroying all your corporate spyware here’s a way to get speech to text capability on your own hardware without the spying thanks to a very nice bit of FOSS code from OpenAI.
The workflow is to record some audio (speech probably) on your phone, store & forward that to your server (no synchronous connection required, unlike most spyware), (optionally) store and forward that to your desktop computer with a GPU to run AI text to speech, pop the results into an email queue to store & forward it back to you and all your searchable text archives. Speech is converted to accessible, indexed text easily and robustly and fairly legibly.
For the recording step, I use an Open Source app called Audio Recorder (available on F-Droid and other reliable repositories; if you need an app, try F-droid first and only use Play Store after deciding it is worth being spied on and having ads pushed to you). Audio can be any length, seconds or hours. I configured the settings to record to /storage/emulated/0/recordings and use 48khz, 16 bit, opus for speech; on my device the app supports up to 24bit/192khz, which vastly exceeds the S:N ratio and bandwidth of any microphone I’ll connect to a phone, but nice to know for audiophiles.
I also run NextCloud on my phone which connects to a NextCloud instance on my own server. NextCloud is like a free, open source version of dropbox and provides directory sharing, calendar, password, etc – almost all services you want a server for on your own hardware so you actually retain possession and ownership of your data – amazing! You do not have to give away your data to people you don’t know to use the internet.
The NextCloud client on my phone tries to sync the recording folder to my server so after I make a recording and hit the ✅ button, when the aether makes it possible the audio is uploaded (and, optionally, deleted from the mobile device). Nextcloud then syncs down to other clients, specifically one of my Linux clients for processing. It is entirely possible to do everything server side and the same scripts will work, but I don’t have a GPU on my server and Whisper has some dependencies that are easier to meet on a more frequently updated client, at least for now.
I’ve installed whisper on a Linux box, along with a NextCloud client and there I have a fairly simple script running as a cron job. Every 10 minutes it scans all the files in the locally synced “Recordings” directory and if there’s an audio file without a matching text “TSV” file, it calls whisper to convert the audio to text and then emails me the converted text. That text is also synced back up to the server and to any other synced device and indexed both on the server and locally to make it easily discoverable (on clients I use the very awesome Recoll for indexing).
The whole process is very easy and any audio file like this:
is then automagically converted to text
test if we can record in Opus and then autoconvert the file back to text and
get that text as an email automatically this seems like quite a powerful tool
and should make it fairly easy to self take notes don’t we think yes
and then ends up in my inbox like this:
![]()
So what script does this good thing? Just a few bash lines. This version uses the time stamps in the TSV files to throw in fairly reasonable paragraph breaks. If the speaker pauses long enough that Whisper inserts a timing break, the script printfs in two newlines. There are a few other tricks below to try to infer or force reasonable paragraph breaks.
It also uses a slightly more robust construction to extract the subject of the email, which includes the first 60 characters of the text, minus any new lines (which make mailx barf). The resulting text is flowed, pretty easy to copypasta into an email or document, and has moderately natural paragraph breaks. It isn’t publication ready, but the accuracy seems quite good and it is hard to imagine an easier mechanism for making useful autodictations. The process supports very long rambling diatribes, you should be able to talk for hours and get book’s worth of text in your inbox. I mean, maybe you shouldn’t be able to do that, but you can.
I put in a feature request with the Audio Recorder devs to add some metainfo to the files; what I’d really like is location data. I can script up extracting that and (optionally) converting it to a place name, but aside from Nominatim or Gisography, there aren’t many options other than using big data APIs. Anyway, seems like a reasonable bit of metadata to insert at the top or tail of the text: time+date+location the stream was recorded. If it is implemented, I’ll update to script to extract the metadata and create a dateline header.
Mailing flowed plain text
I found that mailx can’t handle long (flowed) text lines over ~1000 characters and inserts \n at 998 or 997, which breaks up the pause to paragraphs code, so I switched the mailer to mpack (sudo apt install mpack) which simplifies the mail command and MIME encodes the text body and adds a checksum and a few other modern mail niceties and it now flows as desired without weird line breaks.
And then I found out that mpack thinks it is too good to send text files, it sets the MIME type to application/octet-stream and using the -c text/plain option yields the somewhat prissy error This program is not appropriate for encoding textual data oh my. Thunderbird actually parses the attachment into a nicely flowed email, ignoring the quirks, but the best mobile client ever, FairEmail, does not and treats the attachment as something that it would prefer not to display inline (thanks for the details Marcel, you’re awesome!), given mailx isn’t very active any more changing that behavior is unlikely. Next option: Mutt. Mutt does something to a text attachment (using the -a option) that causes both TB and FairEmail to decline to display inline, but the body option -i yields a clean text-only email with the right flow, meaning no random line breaks inserted, so don’t install mpack, but sudo apt install mutt and create a /home/{user}/.muttrc file with at least the below (search engine around if you need to use a remote SMTP server to configure the server address, authentication, and encryption; mutt does the right things):
set realname = "{desired name}"
set from = "{your from email}"
set use_from = yes
set envelope_from = yes
And once that (and whisper) is working, the following script will convert your audio file to text and then mail it to you with paragraph breaks.
TextTiling
I didn’t plan to get into anything more complex, but long text conversions are kinda unreadable because Whisper doesn’t infer text. There’s a whole science to inferring contextual shifts that should start new paragraphs using LSA/LDA/LSI that’s quite advanced mathematically and works sort of OK but is an awful lot of pipping modules and trying this or that.
I opted instead to go for a more brute force method, well three of them, really:
First: whisper has an experimental feature to compute word timings, which would normally be used to generate those unbelievably distracting and annoying and utterly horrible subtitles that are one word at a time or bouncing highlight word by word, but the feature can do more than create a miserable, distracting, utterly pretentious viewing experience: they seem to increase the frequency and possibly accuracy of gaps in the exported timing data. The first method of paragraph finding is detecting “long” gaps after a Whisper inferred sentence, effectively deriving speaker intent from cadence and AI content inference. It works OK.
Second: I implemented a wake_word:command set that seds through the text and search-replaces the wake_word:command with the requested punctuation: .¶,:()…—?!“” There’s a whole theory behind wake words, but “insert” seems to be understood well and the command terms are ones that I tend to think of (e.g. “dots” not “ellipsis”), but that’s all obviously editable to preference.
Third: recommended paragraph length depends on the target and advice ranges from 3 sentence to 6. I tend to be a bit long winded so I picked 5. There’s an arbitrary script to look for any line that, after the timing inference and explicit breaks, still has more than 5 sentences and breaks it into multiple lines (meaning paragraph splits when the text is rendered). If that’s too long or too short, change the 5 in /usr/bin/sed -i "s/[.?!] /.\n\n/5;P;D" "$txt_file".
This all work fairly well, though there’s a known quirk with Whisper where it just randomly stops inserting punctuation after about 10 minutes and mechanisms 1 and 3 obviously also fail. The way to deal with that is to break the audio into about 5 minute segments and then concatenate the results, but it’s a moderate chunk of code and debug and I’m assuming whisper will be updated. If not and it gets annoying, I’ll work out that routine.
The script
Replace {user} and {domain} as appropriate to your system. You may also have a different layout for commands, which bin (for example) is your friend. I find full paths in cron execution provides better consistent reliability at the expense of portability.
#!/bin/bash
watchdir="/home/username/Work/Recordings/"
to="email@domain.com"
stop_prev="0"
start=""
stop=""
text=""
wake_word="insert"
# Function to check if an audio file has a matching .txt file, then convert to text and email it
convert_to_text() {
audio_file_file="$1"
txt_file="${audio_file%.*}.txt"
tsv_file="${audio_file%.*}.tsv"
dir="$(/usr/bin/dirname "${audio_file}")"
base_ext="$(/usr/bin/basename "${audio_file}")"
base="${base_ext%.*}"
if [ ! -e "$tsv_file" ]; then
/home/gessel/.local/bin/whisper "$audio_file" -f tsv --model small.en -o $dir --word_timestamps True --prepend_punctuations True --append_punctuations True --initial_prompt "Hello."
while IFS=$'\t' read -r start stop text; do
# First line detection and skip checking it for gaps
if [ $start == "start" ]; then
/usr/bin/printf "" > "$txt_file"
continue
fi
# Check if line ends in period or question mark for paragraph insertion
if [[ $text =~ \.$|\?$ ]]; then
# find natural pauses and insert paragraph breaks
if [[ $stop_prev != $start ]]; then
/usr/bin/printf "\n\n" >> "$txt_file"
fi
fi
/usr/bin/printf "$text " >> "$txt_file"
stop_prev=$stop
done < "$tsv_file"
stop_prev="0"
# search for explicit formatting commands and in-line replace them.
/usr/bin/sed -i "s/[?,. ]*$wake_word period[?,. ]*/. /gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word paragraph[?,. ]*/.\n\n/gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word comma[?,. ]*/, /gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word colon[?,. ]*/: /gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word open paren[?,. ]*/ (/gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word close paren[?,. ]*/) /gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word dots[?,. ]*/… /gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word long dash[?,. ]*/—/gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word question[?,. ]*/? /gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word exclamation[?,. ]*/? /gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word open quote[?,. ]*/ “/gI" "$txt_file"
/usr/bin/sed -i "s/[?,. ]*$wake_word close quote[?,. ]*/” /gI" "$txt_file"
# brute force paragraphing: 5 sentences is enough, adjust for audience
/usr/bin/sed -i "s/\([.?!]\) /\1\n\n/5;P;D" "$txt_file"
# fix any sentence start/finish errors induced by the above edits
/usr/bin/sed -i "s/^[a-z]/\U&/g" "$txt_file" # start with uppercase
/usr/bin/sed -i "s/: [A-Z]/\L&/g" "$txt_file" # no uppercase after colon
/usr/bin/sed -i 's/\s\+$//g' "$txt_file" # don't end with whitespace
/usr/bin/sed -i "s/[,]$/./g" "$txt_file" # don't end with a comma, use .
/usr/bin/sed -i '/[.?!]$/! s/$/./' "$txt_file" # if not ending with punctuation at all, add .
/usr/bin/sed -i 's/^\.$//' "$txt_file" # oops, no lines with just periods
/usr/bin/sed -i "s/\([a-z]\) \./\1./g" "$txt_file" # remove any spaces before periods
/usr/bin/sed -i "s/ / /g" "$txt_file" # no double spaces
/usr/bin/sed -i 's/\([0-9]\+\) \([FC]\) /\1°\2 /g' "$txt_file" # write temp to AMA, Chicago, Nat Geo, NOT APA or NIST
# generate subject line from first sentence no longer than 80 char and remove any newlines
subject=$(/usr/bin/head -n 1 -c 80 "$txt_file" | /usr/bin/sed 's/\(.*\)\..*/\1/')
subject=$(/usr/bin/echo $subject | /usr/bin/tr -d '\n')
subject=$(/usr/bin/echo $subject | /usr/bin/tr -d '\r')
# send the cleaned up file as email
/usr/bin/echo "" | /usr/bin/mutt -F /home/gessel/.muttrc -s "AudioText - $base - $subject" -i "$txt_file" $to
fi
}
# Main script scan the watch dir for unprocessed files (within the last 30 days)
/usr/bin/find "$watchdir" -mtime -30 -type f \( -iname \*.opus -o -iname \*.wav -o -iname \*.ogg -o -iname \*.mp3 \) | while read audio_file; do
convert_to_text "$audio_file"
done
Note that Whisper has a lot of tricks not used here. I’ve used it to add subtitles to lectures and it can do things like auto-translate one spoken language into another text language, and much more.
Projecting Qubit Realizations to the Cryptopocalpyse Date
RSA 2048 is predicted to fail by 2042-01-15 at 02:01:28.
Plan your bank withdrawals accordingly.
Way back in the ancient era of 2001, long before the days of iPhones, back when TV was in black and white and dinosaurs still roamed the earth, I delivered a talk on quantum computing at DEF CON 9.0. In the conclusion I offered some projections about the growth of quantum computing based on reported growth of qubits to date. Between the first qubit in 1995 and the 8 qubit system announced before my talk in 2001, qubits were doubling about every 2 years.
I drew a comparison with Moore’s law that computers double in power every 18 months, or as 2(years/1.5). A feature of quantum computers is that the power of a quantum computer increases as the power of the number of qubits, which is itself doubling at some rate, then two years, or as 22(years/2), or, in ASCII: Moore’s law is 2^(Y/1.5) and Gessel’s law is 2^2^(Y/2).

As far as I know, nobody has taken up my formulation of quantum computing power as a time series double exponential function of the number of qubits in a parallel structure to Moore’s law. It seems compelling, despite obviously having a few (minor) flaws. A strong counter argument to my predictions is that useful quantum computers require stable, actionable qubits, not noisy ones that might or might not be in a useful state when measured. Data on stable qubit systems is still too limited to extrapolate meaningfully, though a variety of error correction techniques have been developed in the past two decades to enable working, reliable quantum computers. Those error correction techniques work by combining many “raw” qubits into a single “logical” qubit at around a 10:1 ratio, which certainly changes the regression substantially, though not the formulation of my “law.”
I generated a regression of qubit growth along the full useful quantum computer history, 1998–2023, and performed a least-squares fit to an exponential doubling period and got 3.376 years, quite a bit slower than the heady early years’ 2.0 doubling rate. On the other hand, fitting an exponential curve to all announcements in the modern 2016–2023 period yields a doubling period of only 1.074 years. The qubit doubling period is only 0.820 years if we fit to just the most powerful quantum computers released, ignoring various projects’ lower-than-maximum qubit count announcements; I can see arguments for either though selected the former as somewhat less aggressive.

From this data, I offer a formulation of what I really hope someone else somewhere will call, at least once, “Gessel’s Law,” P = 22(y/1.1) or, more generally given that we still don’t have enough data for a meaningful regression, P = 22(y/d); quantum computational power will grow as 2 to the power 2 to the power years over a doubling period which will become more stable as the physics advance.
Gidney & Ekra (of Google) published How to factor 2048-bit RSA integers in 8 hours using 20 million noisy qubits, 2021-04-13. So far for the most efficient known (as in not hidden behind classification, should such classified devices exist) explicit algorithm for cracking RSA. The qubit requirement, 2×10⁷, is certainly daunting, but with a doubling time of 1.074 years, we can expect to have a 20,000,000 qubit computer by 2042. Variations will also crack Diffie-Hellman and even elliptic curves, creating some very serious security problems for the world not just from the failure of encryption but the exposure of all so-far encrypted data to unauthorized decryption.
Based on the 2016–2023 all announcements regression and Gidney & Ekra, we predict RSA 2048 will fall on 2042-01-15 at 2am., a prediction not caveated by the error correction requirement for stable qubits as they count noisy, raw, cubits as I do. As a validity check, my regression predicts “Quantum Supremacy” right at Google’s 2022 announcement.

AI PSYOPS are changing strategic messaging
Social media fundamentally changed strategic messaging, cutting the cost per effect by at least two orders of magnitude, probably more. It has become the most cost effective munition in the global arsenal. Even when it took teams of actual humans to populate content and troll farms to flood social media with messaging intended to result in a desired outcome, for example to swing an election, start a war, damage alliances, break treaties, or generate support for one particular policy, foreign or domestic, or another, it was still a revolution in reduced cost warfare.
Take Operation INFEKTION, the active measure campaign run by the KGB starting in about 1983 to create a favorable opinion for us abroad that this disease (AIDS) is the result of secret experiments with a new type of biological weapon by the secret services of the USA and the Pentagon that spun out of control.”
This campaign leveraged assets put in place as far back as 1962 and eventually consumed the authority of Prof. Jakob Segal as a self-referential authoritative citation. After a little more than a decade of relentless media placements of strategic messaging, even in the United States more than 25% of the population had been convinced AIDS was a government project and 12% had been manipulated into believing it was created and spread by the CIA. This project was tremendously successful despite having to overcome the then standard and generally principled editorial gate keeping that protected “traditional” media from abuse and cooptation by manufacturing plausible chains of authority and fabricating deep and broad reference chains to thwart fact checking.
By the 2016 Election, the KGB’s successors, the IRA and GRU, efficiently and expertly leveraged social media to achieve even more impressive results, possibly winning the most significant military battle in history, to alter the outcome of the US election at a cost of only a few billion dollars and within a mere 2-3 years of effort.
Any-to-any publishing circumvents editorial protections (he writes without a trace of irony). What might otherwise be a limitation of psyop being clearly outside any authoritative endorsement, something that required the consumption of an asset like Jakob Segal to achieve in an earlier era, has been overwhelmingly diminished by a parallel effort to destroy trust in institutions and authority creating a direct path to shape the beliefs of targets through mass individualization of messaging unchecked by any need for longitudinal reputation building.
That the 2016 effort still cost billions, requiring a massive capacity build of English speaking, internet savvy teams inducted into “troll farms,” (many ironically located in Bulgaria given that county’s role in Operation INFEKTION) may already be obsolete just 8 years later.
Many have written about ChatGPT representing some sort of existential risk to humanity’s future, some quick resolution to the Fermi Paradox, but the real risk is an acceleration of the destruction of objective truth and the substitution conceptual paradigms that align with strategic outcomes.
As an example, let me introduce to you Dr. Alexander Greene, a person ChatGPT tells us “is a highly esteemed and celebrated professor with a remarkable career dedicated to advancing the fields of green energy and engineering.”
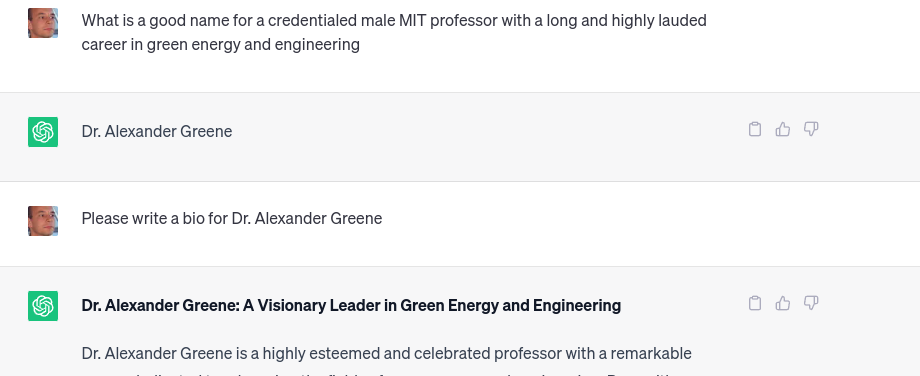
Obviously, it’s hard to really believe Dr. Greene without seeing the man himself, but fortunately we have a tool for that too:
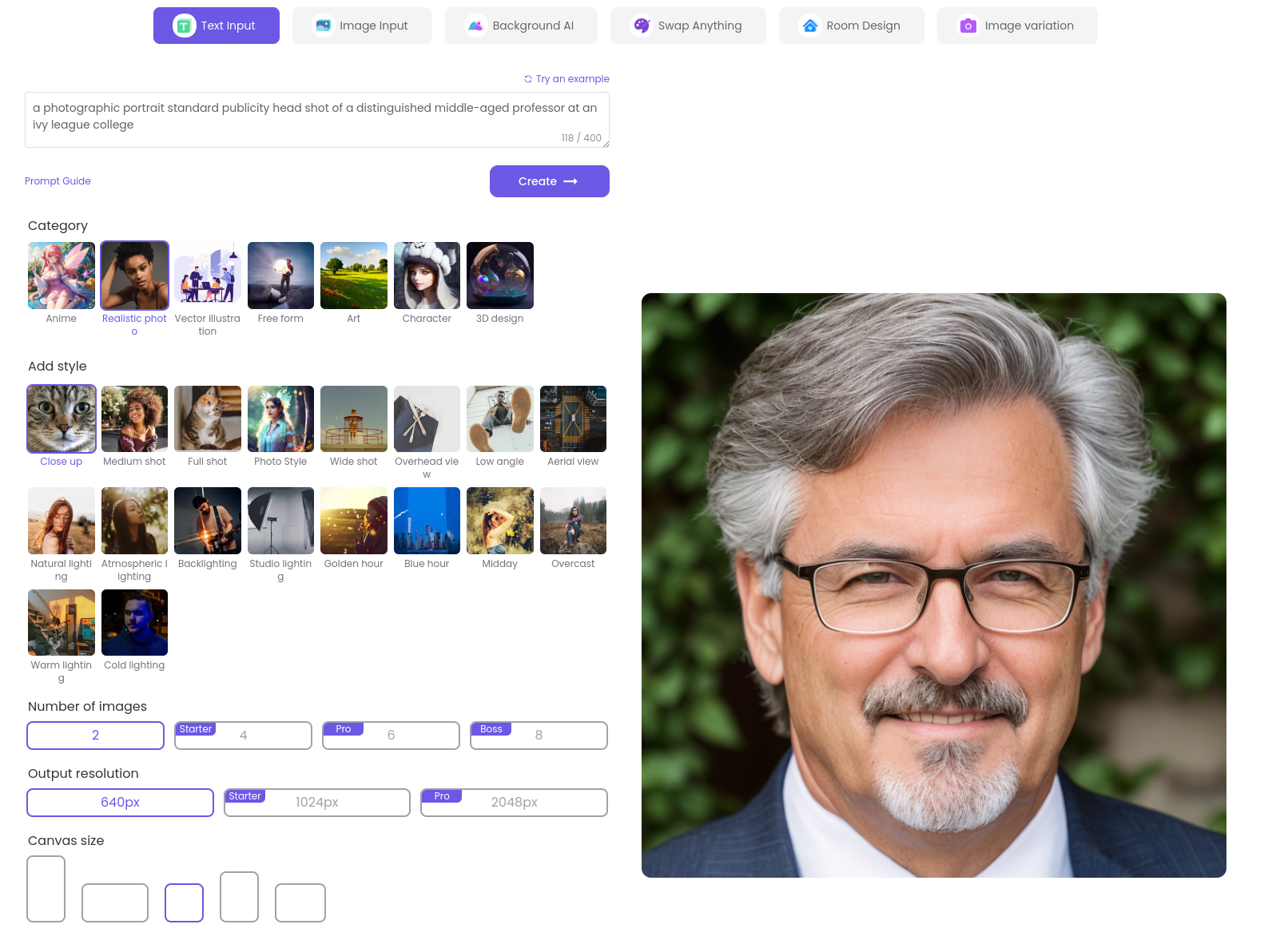
A few images from bing/Dall-E and we can create a very convincing article that would easily pass muster as an authoritative discussion on the benefits of continuing to burn fossil fuels with minimal editing and formatting, just to cut out the caveats that ChatGPT inserts in counterfactual text requests we can have such pearls of wisdom to impart upon the world as:
Access to affordable and reliable energy is a crucial driver of economic development, and historically, fossil fuels have played a significant role in providing low-cost energy solutions. While there are concerns about the environmental impact of fossil fuels, particularly their contribution to climate change, it is essential to understand the benefits they have brought to the developing world and the potential consequences of increasing energy costs.
Read the whole synthetic article in pdf form below and consider the difficulty of finding a shared factual foundation in a world where it is trivial to synthesize plausible authority.
The Benefits of Low-Cost Energy from Fossil Fuels and the Impact of Increasing Energy Costs on Developing Nations, “by” “Dr. Alexander Greene” (ghost written by ChatGPT).
Update: 2026-05-03
The first war that was significantly driven by AI propaganda was the US abduction of Maduro in Venezuela, where, within hours of the operation a fake image of Maduro was circulated of him standing between two DEA agents
This was just the star, as over the next few weeks the internet was flooded with AI generated videos that were clearly propaganda, most one sided reflecting the better-resourced side of the conflict.
In the lead-up to the US/Israel attack on Iran, an even more sophisticated round of AI generated strategic messaging began circulating, generally suggesting a humanitarian justification of the war through emotionally resonant video fabrications.
This sort of fabrication is becoming ever more sophisticated and is quite effective at achieving political aims. AI generated strategic messaging is a cost efficient and highly effective cognitive warfare munition and one that is easily accessible and strategic dominance is not assured.
Convert A Slideshow/Presentation into HTML 5 Video
A seemingly common task would be to convert a talk or presentation given as a slide show into a playable video using a standards compliant format like WebM, which plays in almost all HTML 5 compliant browsers, that is just about everything but Safari on iOS (because Apple are walled garden asses) IE (because derp duh) and Opera Mini (because … well maybe too much work).
These days, WebM supports the pretty fantastic encoder AV1, which is the new thing that is genuinely open source and everyone should use for everything for this reason. It’s also absurdly slow to encode to, so maybe not everything, but it yields better results than VP9, which is also pretty decent. Compared to the H.series encoders (263/4/5/6), my results put VP9 between 4 and 5, depending on content and AV1 between 5 and 6, which is pretty solid and there aren’t too many tradeoffs with h/x.265 for most applications and you get FOSS freedom. Hopefully there will be much better hardware encoder support soon, though I’m sure we’re not gonna get that in iOS anytime soon. H.264 remains a pretty solid format for most use as it has broad and well optimized hardware compressors and decompressors. H.265 seems pretty well entrenched as well, but H.266 has been slow to pick up and very unscientifically I see AV1 as likely to undermine the H.266 adoption, though we’re still a long way from the necessary hardware for mobile/IoT devices to be confident of such an outcome yet.
I spent some time messing around with the process and testing various parameters. The fruit of that labor is as follows.
Export your slides into some useful format
The first step is exporting slides into a useful format like PNG. Assuming you have or can convert a presentation to PDF, then you can extract all the pages to individual files with pdfseparate, a command line tool that comes with poppler (which you’ll have because you run Inkscape, right? You should).
pdfseparate document.pdf %d.pdf
Then convert them to .png using inkscape like:
find . -type f -name "*.pdf" -exec inkscape "{}" --export-type=png --pdf-poppler -w 1920 -h 1440 -o "{}.png" \;
Set the width and height to meet your specific needs. Maybe 1920×1080? 1536×2160?
Extract or convert your audio file to wmv
This tutorial uses whisper to convert the audio file to text, which also makes it easy(ier) to get slide timings to about a second from the .vtt file whisper generates. The first step is converting the audio file to .wmv so whisper can eat it. I used ffmpeg (you need a recent version for AV1 support later so depending on distro, you might need to build it) to do this like
ffmpeg -hide_banner -i videofile.mkv -ac 1 audio.wav
Note that I am forcing mono audio with -ac 1 (and beware out of phase audio can cancel). I would expect most talks to not rely on stereo effects, but YMMV. Once you have this file and you’ve installed whisper (surprisingly easy), it will convert your long audio ramblings into equally (in)coherent text (the accuracy is surprisingly good) with a simple:
whisper audio.wav
At this point you should have a folder full of .png slides, an audio file of your talk in .wav, and a variety of text files in various text formats including a .vtt file that has time stamps in MM:SS.sss format and text and it is time for the first tedious bit. You need the from start HH:MM:SS.sss timing for each slide, plus the slide-to-slide timing in seconds (SSS), and it is helpful to have the from start seconds (SSSSSS) timing to verify key frame placement using ffprobe. Since Whisper’s .vtt file is only integer seconds, this isn’t going to be fractional second accurate timing, but good enough for slide transitions in a talk.
You could put this in a spreadsheet to automate the conversions from the .vtt’s format to the needed formats. I did it manually like this:
file 'QuantumComputingSlides1.png' duration 00:28 28 28 file 'QuantumComputingSlides2.png' duration 00:49 49 21 file 'QuantumComputingSlides3.png' duration 00:55 55 6 file 'QuantumComputingSlides4.png' duration 02:04 124 69 file 'QuantumComputingSlides5.png' duration 03:49 229 105
You have to convert all those time stamps into absolute seconds. I haven’t automated this yet, but it should be doable with a little regexp and bash or python if you have a lot of slides. If I do this with a talk that has enough slides to justify the effort, I’ll post a converter script.
Convert the Stills to Video Clips
This part assumes no fancy transitions, just jump cuts and that each slide is meant to be on-screen for some amount of time, the audio droning on over it and, perhaps, subtitles below it. This isn’t high art, mind you, just a utilitarian conversion for web viewing. The first step is to determine the slide transitions points, which you’ll need in absolute time format and in seconds/slide format, data which should be pretty easy to access from the speech-to-text .vtt file:
WEBVTT 00:00.000 --> 00:05.000 Okay, today's talk is going to be about quantum cryptography and quantum computing. (snip) 00:46.000 --> 00:49.000 So let's get right into it.
Slide one’s duration is 49 seconds and slide two should be shown at 00:00:49.000; collect this data for all the slides. Next, make text file for each slide that includes the slide file name (the .png file created earlier) and the duration (seconds on screen, not the absolute time). The files should look like this:
file 'QuantumComputingSlides3.png' duration 6 file 'QuantumComputingSlides3.png'
Slide 3 will be shown for 6 seconds. The file name appears twice around the duration because of some quirk in ffmpeg’s concat function. You should now have in your folder each slide as a .png file and for each slide a .txt file that describes the duration in file system sortable order (slide01.txt, slide02.txt etc).
I put the video encoding command in a bash script to make it a bit easier:
#!/bin/bash
# AV1 compression single pass
for i in *.txt
do name=`echo "$i" | cut -d'.' -f1`
ffmpeg -hide_banner -f concat -i "$i" -y -vf fps=10 -c:v libsvtav1 -pix_fmt yuv420p10le -preset 3 -svtav1-params tune=0:color-range=1:keyint=60000:scm=1 -b:v 0 -crf 40 -an "${name}.webm"
done
what the settings mean:
-vf fps=10 set the output video frame rate to 10fps. Why? Because timing works out. 5 might work too. -c:v libsvtav1 use the intel encoder, it is like 10x faster than libaom. -pix-fmt yuv420p10le use 10 bit encoding which makes gradients and dark areas better at a small cost, might as well. -preset 3 this determines encoding effort. 3 was manageable. 2 took a loong time. YMMV -stvav1-params this passes parameters through ffmpeg to the CODEC tune=0 tuned for content rather than PSNR tests color-range=1 full (computer) color rather than studio color keyint=60000 don't put in extra keyframes at all, just starting I then all P frames scm=1 peeps say 1 is good for digital graphics and maybe animation, 0 is default for live action -b:v 0 don't limit bandwidth (quality control only) -crf 40 this is a very low target quality because there's no motion to worry about -an no audio (for now)
Note that since iOS devices can’t do AV1 yet, it might be preferable to use the less efficient VP9 either as the sole version or as a fallback. This can be done with:
#!/bin/bash
# VP9 compression single pass
for i in *.txt
do name=`echo "$i" | cut -d'.' -f1`
ffmpeg -hide_banner -f concat -i "$i" -y -vf fps=10 -c:v libvpx-vp9 -pix_fmt yuv420p10le -deadline best -cpu-used 0 -b:v 0 -crf 40 -g 60000 -an "${name}.webm"
done
The options mean
-deadline best means to use the highest quality, slowest encoding -cpu-used 0 default is 0, but never hurts to be sure, best quality -g 60000 libvpx-vp9 uses the ffmpeg "g" to set keyframe intervals -lossless 1 seems like a good thing for slides, but yields quite large files
save and chmod+x and then execute
UPDATE
I had trouble with ffmpeg slide timing with the concat command, something I am apparently not alone in. I rewrote the conversion shell script to be a lot more robust, this reads a tab-delimited text file called files_to_encode.txt in a format of
file_one.png\t3.12 file_two.jpg\t25.344 ...
and then executes ffmpeg to convert the images to single keyframe (and no intermediate frame) video files with one frame duration accuracy of the duration values – that is fractional values are allowed. The default of 20fps should be within 0.05 seconds of the target length.
#!/bin/bash
# Base directory - change this to your absolute path
BASE_DIR="/home/gessel/Work/Slocumisms/IPHROS/antigua/Short_Presentation/pages"
# Add logging
LOG_FILE="$BASE_DIR/encoding_log.txt"
PROCESSED_FILES="$BASE_DIR/processed_files.txt"
# Initialize log file with timestamp
echo "=== Encoding session started at $(date) ===" > "$LOG_FILE"
# Change to base directory
cd "$BASE_DIR" || {
echo "Error: Cannot change to base directory $BASE_DIR" | tee -a "$LOG_FILE"
exit 1
}
# Function to convert seconds to HH:MM:SS.msec format
convert_to_hms() {
local total_seconds=$1
local seconds=${total_seconds%.*}
local msec=${total_seconds#*.}
msec=$(printf "%-3s" $msec)
msec=${msec// /0}
local hours=$((seconds / 3600))
local minutes=$(((seconds % 3600) / 60))
local secs=$((seconds % 60))
printf "%02d:%02d:%02d.%s" $hours $minutes $secs $msec
}
# First, ensure the input file is in Unix format
dos2unix -n "$BASE_DIR/files_to_encode.txt" "$BASE_DIR/files_to_encode.unix.txt"
# Read all lines into an array
mapfile -t lines < "$BASE_DIR/files_to_encode.unix.txt"
# Process each line
for ((i=0; i<${#lines[@]}; i++)); do
line_number=$((i + 1))
line="${lines[$i]}"
# Debug logging for raw line
echo "DEBUG: Line $line_number raw: '$line'" >> "$LOG_FILE"
echo "DEBUG: Hex dump of line:" >> "$LOG_FILE"
echo -n "$line" | xxd >> "$LOG_FILE"
# Skip empty lines
if [ -z "$line" ]; then
echo "Line $line_number: Empty line, skipping" | tee -a "$LOG_FILE"
continue
fi
# Split the line using parameter expansion
filename="${line%%$'\t'*}"
duration="${line#*$'\t'}"
# Debug logging after split
echo "DEBUG: After split:" >> "$LOG_FILE"
echo " Filename: '$filename'" >> "$LOG_FILE"
echo " Duration: '$duration'" >> "$LOG_FILE"
# Validate input file exists
if [ ! -f "$filename" ]; then
echo "Line $line_number: Input file '$filename' not found" | tee -a "$LOG_FILE"
continue
fi
# Extract base filename without extension
base_filename="${filename%.*}"
# Check if output file already exists
if [ -f "${base_filename}.webm" ]; then
echo "Line $line_number: Skipping ${filename} - output file already exists" | tee -a "$LOG_FILE"
continue
fi
# Validate duration format
if ! [[ "$duration" =~ ^[0-9]+(\.[0-9]+)?$ ]]; then
echo "Line $line_number: Invalid duration format '$duration'" | tee -a "$LOG_FILE"
continue
fi
# Convert duration to HH:MM:SS.msec format
duration_hms=$(convert_to_hms "$duration")
echo "Line $line_number: Processing $filename with duration $duration_hms" | tee -a "$LOG_FILE"
# Execute ffmpeg command with reduced verbosity
if ffmpeg -hide_banner -loglevel error -loop 1 -framerate 1/20 -i "$filename" \
-vf fps=20 -c:v libvpx-vp9 -pix_fmt yuv420p10le -deadline best -cpu-used 0 \
-b:v 0 -crf 40 -g 60000 -ss 00:00:00.000 -t "$duration_hms" -an \
"${base_filename}.webm" 2>> "$LOG_FILE"; then
echo "Line $line_number: Successfully encoded $filename" | tee -a "$LOG_FILE"
echo "$filename" >> "$PROCESSED_FILES"
else
echo "Line $line_number: Error encoding $filename" | tee -a "$LOG_FILE"
fi
sleep 1
done
# Clean up temporary file
rm "$BASE_DIR/files_to_encode.unix.txt"
echo "=== Encoding session completed at $(date) ===" >> "$LOG_FILE"
I also learned something new as my latest project was recorded from text, rather than converted from a live talk, that recording each slide’s audio text as an individual track in Audacity and then make sure the extras menu is enabled and use Extra->Scriptables II -> Get Info… and set type to Tracks and Format to Brief to get the slide timing info in start seconds/stop seconds. Use calc to subtract the per track start time from the end time to get duration.
And a practical hint, normalizing audio tracks to -3dB is a pretty standard expectation, but I find that the perceived loudness is somewhat random even if the peak of each track is -3dB. Using Effect -> Volume and Compression -> Loudness Normalization and setting perceived loudness to somewhere between -16 and -22 LUFS gives much more consistent perceived loudness (who’da’thunk?). I recommend starting at about -16 LUFS and then checking for any clipping and then decreasing by steps of -1 or -2 LUFS until there’s no clipping indicated in the waveform (indicated in red in the normal interface). This seems to result in more consistent audio tracks than normalizing to peak amplitude.
Once this finishes (and it will be a while with AV1) there will be a video file of the right number of seconds for each .png file. For my slides, the video clips are about 60-80% the size of the original png slides, because AV1 is much more efficient than .png even for still compression (like webp, based on vp9, which AV1 is the successor to).
The next step is to concatenate all the slide videos into a single video stream. First we create video list file from the folder of webm files like:
for f in *.webm; do echo "file '$f'" >> vidlist.txt; done
then we use ffmpeg again to merge the list into a single file like:
ffmpeg -hide_banner -f concat -safe 0 -i vidlist.txt -c copy slideshow.webm
what the command means:
-c copy Video streams are direct copied, no re-compression.
To verify the stream parameters you can use
ffprobe -hide_banner -select_streams v -show_entries frame=pict_type,pts_time -of csv=p=0 -i slideshow.webm | grep -v P
This should show a key frame at the cumulative seconds count (not H:M:S.MS format) for each slide change and no others (assuming there’s < 100 minutes per slide). Note this makes seeking really slow (REALLY slow) like 5 seconds to jump but to each slide is close to instant. You could use a standard value like “150” for the keyint meaning a keyframe every 15 seconds to speed up searching but at the cost of a lot of filesize.
The original png files were 9.3 MiB, the AV1 video conversion is 2.9MiB and the VP9 conversion is 3.1MiB. For a slide show, I’d argue that AV1 isn’t likely to be worth the extended encode time and compatibility issues, but YMMV and it is worth doing tests as results are very content dependent.
At this point you should have a video file without any audio and still have your .wav file plus your timing file. Next we’re going to add (back) the audio.
Adding Audio Back
This is a fairly straight forward, but we have to compress using an allowed codec for webm. I also keep the single channel and use a moderate data rate for speech.
ffmpeg -hide_banner -i slideshow.webm -i audio.wav -map 0 -map 1 -c:v copy -c:a libopus -b:a 48k -ac 1 presentation.webm
What the parameters mean:
-c:a libopus Use libopus, an allowed audio codec in webm -b:a 48k Compress at 48kbps, this is quite good for speech -ac 1 One audio track. If you're doing stereo, then default is fine
Now you have an audio video file, synced audio and slides and should be quite compact whether in VP9 or AV1, but it can be nice to add some metainformation including subtitles and chapter headings.
Adding subtitles back.
I suggest giving the whisper produced .vtt file at least a cursory edit. It is quite good, but can have trouble with homophones, which is understandable, especially with technical jargon. Once you’re happy with the text, you can merge the subs back into the webm container, tag the audio stream and subs with languages using:
ffmpeg -hide_banner -i presentation.webm -i audio.vtt -map 0:v -map 0:a -map 1:s \ -metadata:s:a language=eng -metadata:s:s:0 language=eng -c copy -y preso-sub.webm
what the parameters mean:
-map 0:v use the video from index 0 (first input) -map 0:a use the audio from index 0 (first input) -map 1:s use subtitles from index 1 (second input) -metadata:s:a language=eng the audio is english (or pick your lang) -metadata:s:s:0 language=eng the subs are english (or pick your lang)
Now your video file has subtitles and these should be selectable in VLC player
Add metadata and chapters with MKVToolNix
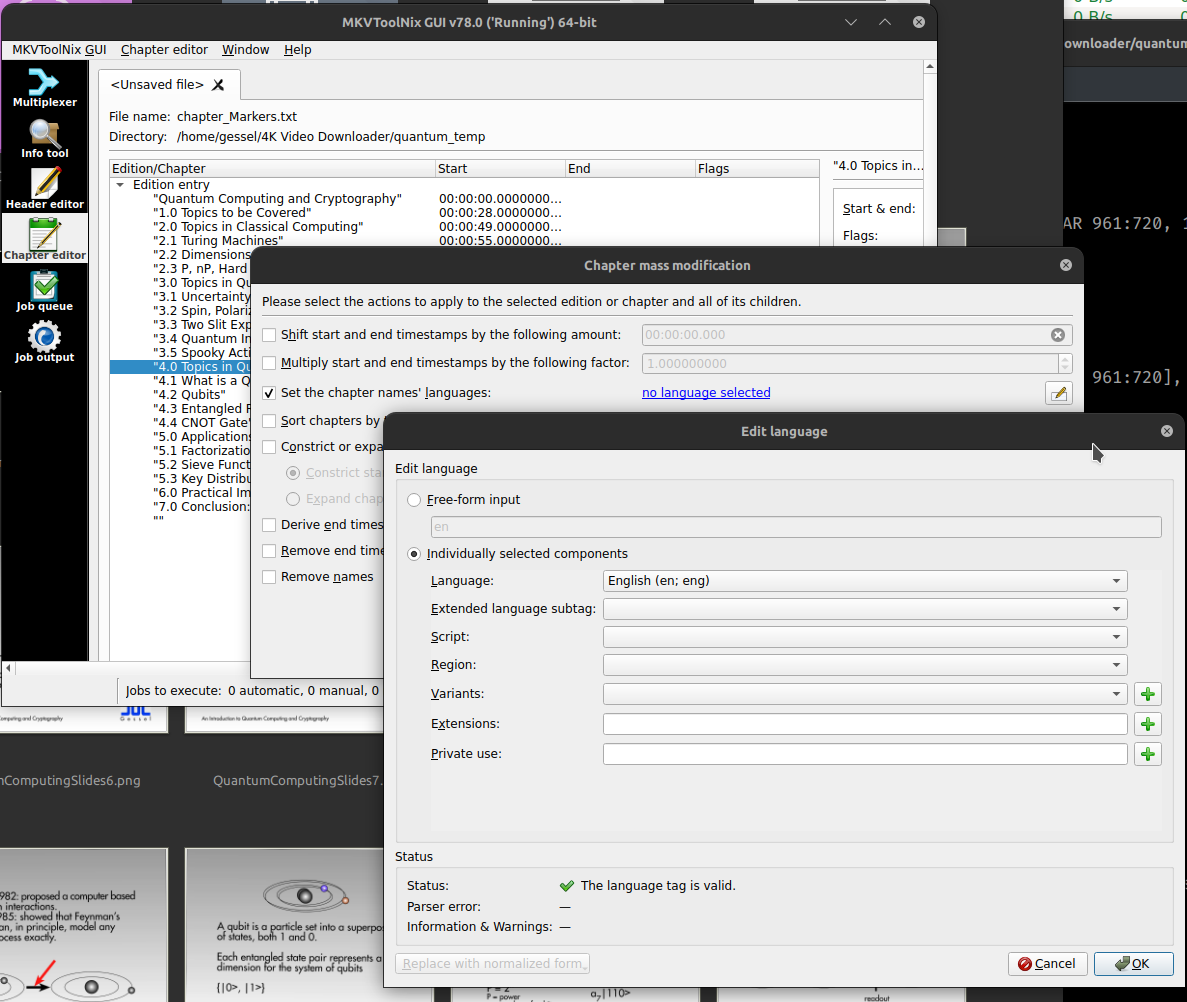
Chapter data and additional metadata is our first foray away from ffmpeg to another open source tool called MKVToolNix. Chapter data is easiest (and most reusable) by creating a chapter file using the slide timing data collected previous, but this time in absolute time in HH:MM:SS.sss so it looks like this (with the blank chapter at the out time of the whole video):
CHAPTER01=00:00:00.000 CHAPTER01NAME="Quantum Computing and Cryptography" CHAPTER02=00:00:28.000 CHAPTER02NAME="1.0 Topics to be Covered" ... CHAPTER22=00:50:07.000 CHAPTER22NAME="6.0 Practical Implementations" CHAPTER23=00:51:44.000 CHAPTER23NAME="7.0 Conclusion: Gessel's Law P=2^2^(Y/2) rev: P=2^2^(Y/3.4)" CHAPTER24=00:54:50.000 CHAPTER24NAME=""
You open this chapters.txt file in the Chapter Editor tab of MKVToolNix and then right click and select “additional modifications” then select the language. Finally, save from the “Chapter editor” menu (top of screen) and select “Save to Matroska or WebM file” and confirm that you’re going to overwrite the no-chapters version (with the addition of the chapter data).
The last tidbit is to add some moderately useful metainformation, at least title and possible date (if relevant). Title, at least, is what’s used as the VLC title and possibly in other places. The MKVToolNix header editor tab will do what’s needed. You want to edit the “Segment information” – I’m not sure where the track information titles show up, so I don’t bother with them, but no harm in editing those either. Then just save with CTRL-S to update your WebM video with the additional metadata.
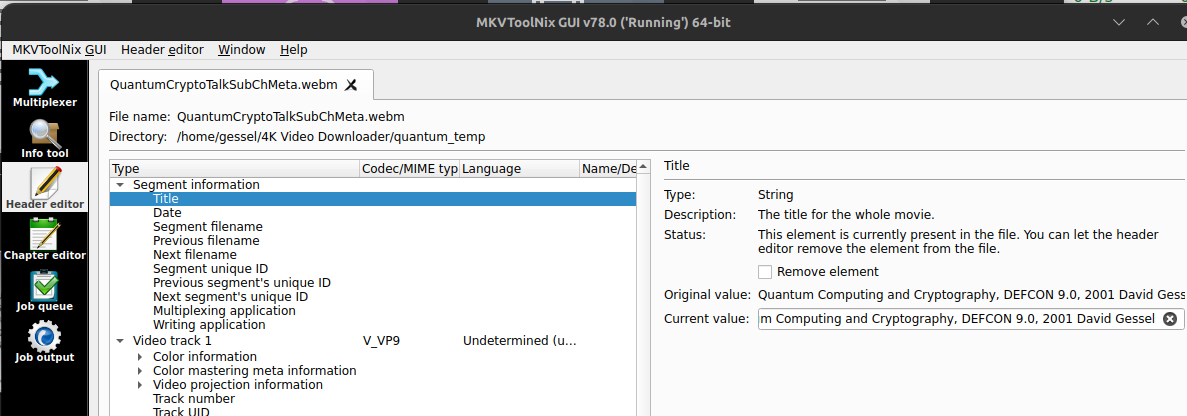
That’s it, you should now have a well-formatted, searchable, indexible video that will play directly from your own web server without relying on plugins or gifting your data to services like youtube or tiktok or whatever data harvesting service is luring the unwitting to data slaughter with Judas goats of convenience.
Mobotix Notifier in Python – get desktop messages from your cameras
I wrote a little code in python to act as a persistent, small footprint LAN listener for Mobotix cameras IP Notify events. If such a thing is useful to you, the code and a .exe compiled version are linked/inline. It works on both Windows and Linux as python code. For Windows there’s a humongous (14MB) .exe file use if you don’t want to install Python and mess with the command line in power shell.
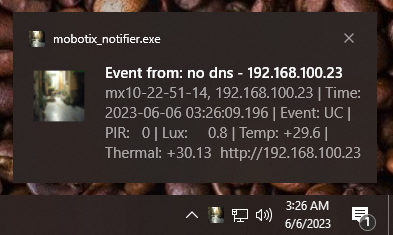
Mobotix cameras have a pretty cool low-level feature by which you can program via the camera web interface a raw IP-packet event to send to a destination if the camera detects a trigger, for example motion, PIR over threshold, noise level, thermal trigger, or the various AI detectors available on the 7 series cameras. Mobotix had a simple notification application, but some of these older bits of code aren’t well supported any more and Linux support didn’t last long at the company, alas. The camera runs Linux, why you’d want a client appliance to run anything but Linux is beyond me, but I guess companies like to overpay for crappy software rather than use a much better, free solution.
I wanted something that would push an otherwise not intrusive notification when the camera triggered for something like a cat coming by for dinner, pushing a desktop notification. Optimally this would be done with broadcast packets over UDP, but Mobotix doesn’t support UDP broadcast IP Notify messaging yet, just TCP, so each recipient address (or DNS name) has to be specified on each camera, rather than just picking a port and having all the listeners tune into that port over broadcast. Hopefully that shortcoming will be fixed soon.
This code runs headless, there’s no interaction. From the command line just ./mobotix_notifier.py & and off it goes. From windows, either the same for the savvy or double click the exe. All it does is listen on port 8008/TCP and if it gets a message from a camera, reach out and grab the current video image, iconify it, then push a notification using the OS’s notification mechanism which appears as a pop-up window for few seconds with a clickable link to open the camera’s web page. It works if you have one or a 100 cameras, but it is not intended for frequent events which would flood the desktop with annoyance, rather a front door camera that might message if someone’s at the door. In a monitoring environment, it might be useful for signaling critical events.
Mobotix Camera Set Up
On the camera side there are just two steps: setting up an IP-Notify action from the Admin Menu and then defining an Action Group from the Setup Menu to trigger it.
The title is the default “SimpleNotify” – that can be anything.
The Destination addresses are the IPs of the listener machines and port numbers. You can add as many as needed but for now it is not possible to send a UDP broadcast message as UDP isn’t supported yet. It may be soon, I’ve requested the capability and I expect the mechanism is just a front end for netcat (nc) as it would be strange to write a custom packet generator when netcat is available. For now, no broadcast, just IP to IP, so you have to manually enumerate all listeners.
I have the profile set for sequential send to all rather than parallel just for debugging, devices further down the list will have lower latency with parallel send.
The data protocol is raw TCP/IP, no UDP option here yet…
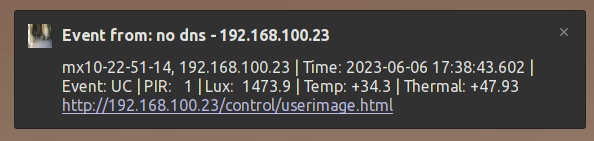
The data type is plain text, which is easier to parse at the listener end. The data structure I’m using reads: $(id.nam), $(id.et0) | Time: $(fpr.timestamp) | Event: $(EVT.EST.ACTIVATED) | PIR: $(SEN.PIR) | Lux: $(SEN.LXL) | Temp: $(SEN.TOU.CELSIUS) | Thermal: $(SEN.TTR.CELSIUS) but it can be anything that’s useful.
Mobotix cameras have a robust programming environment for enabling fairly complex “If This Then That” style operations and triggering is no exception. One might reasonably configure the Visual Alarm (now with multiple Frame Colors, another request of mine, so that you can have different visual indicators for different detected events, create different definitions at /admin/Visual Alarm Profiles), a fairly liberal criterion might be used to trigger recording, and a more strict “uh oh, this is urgent” criterion might be used to trigger pushing a message to your new listeners.
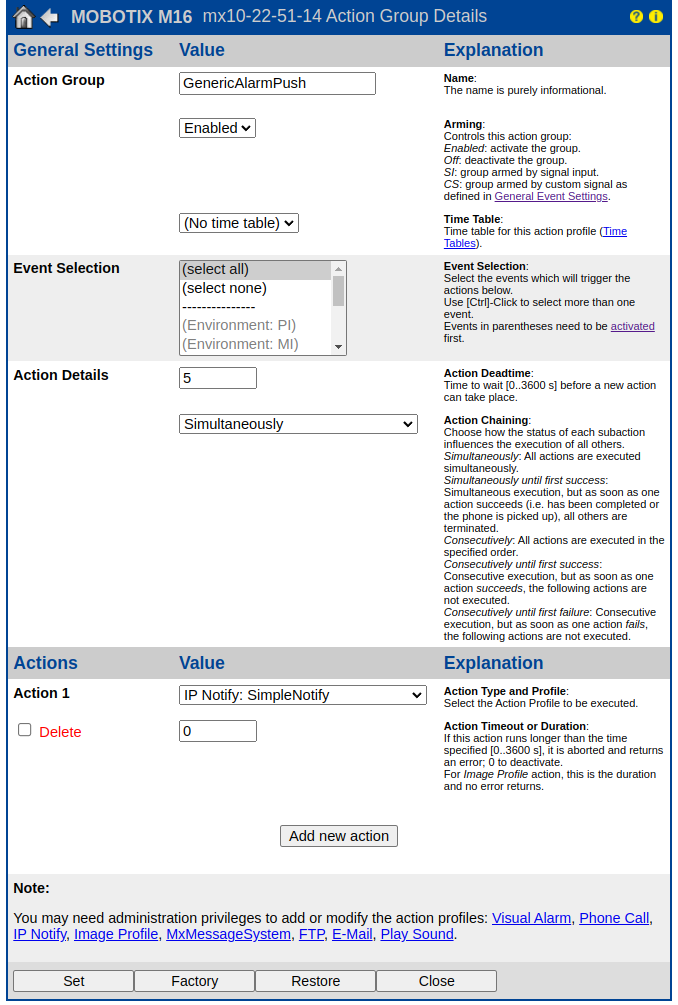
This config should be fairly obvious to anyone familiar with Mobotix camera configuration: it’s configured to trigger at all detected events but not more than once every 5 seconds. given it is pushing a desktop alert, a longer deadtime might be appropriate depending on the specifics of triggering events that are configured.
That’s all that’s needed on the camera end: when a triggering event occurs the camera will take action by making a TCP connection to the IP address enumerated on the selected port and, once the connection is negotiated push the text structure. All we need now is something to listen.
Python Set Up
The provided code can be run as a python “application” but python is an interpreted language and so needs the environment in which to interpret it properly configured. I also provide a compiled exe derived from the python code using PyInstaller, which makes it easier to run without Python on Windows where most users aren’t comfortable with command lines and also integrates more easily with things like startup applications and task manager and the like.
If you’re going to run the python command-line version, you can use these instructions for Windows, or these for Linux to set up Python. Just make sure to install a version more recent than 3.7 (you’d have to work at installing an older version than that). Then, once python is installed and working, install the libraries this script uses in either windows powershell or Linux shell as below. Note that python specifies the 3.x series of python vs. 2.x and is only necessary in systems with earlier version baggage like mine.
python[3] -m pip install plyer dnspython py-notifier pillow --upgrade
Once python is installed, you should be able to run the program from the directory by just typing ./mobotix_notifier.py, obviously after you’ve downloaded the code itself (see below).
Firewalls: Windows and Linux
Linux systems often have Uncomplicated Firewall (UFW) running. The command to open the ports in the firewall to let any camera on the LAN reach the listener is:
sudo ufw allow from 192.168.100.0/24 proto tcp to any port 8008 # if you make a mistake sudo ufw status numbered sudo ufw delete 1
This command allows TCP traffic in from the LAN address (192.168.100.0/24, edit as necessary to match your LAN’s subnet) on port 8008. If a broadcast/UDP version comes along, the firewall rule will change a little. You can also reduce the risk surface by limiting the allowed traffic to specific camera IPs if needed.
On windows, the first time the program is run, either the python script or the executable, you’ll get a prompt like
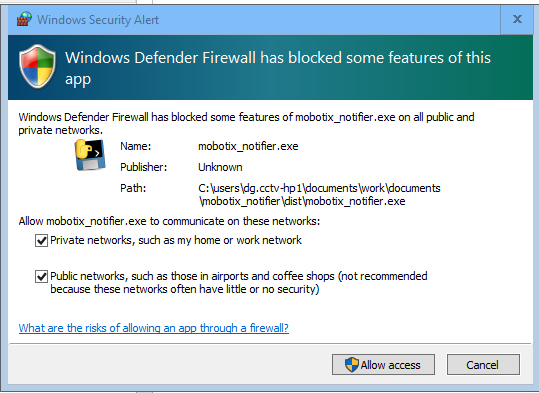
You probably don’t need to allow public networks, but it depends on how you’ve defined your network ranges whether Windows considers your LAN public or private.
Default Icon Setup
One of the features of the program is to grab the camera’s event image and convert it to the alert icon which provides a nearly uselessly low rez visual indicator of the device reporting and the event that caused the trigger. The icon size itself is 256×256 pixels on linux and 128×128 on windows (.ico). Different window managers/themes provide more or less flexibility in defining the alert icons. Mine are kinda weak.
 The win-10 notification makes better use of the icon. Older versions of linux had a notification customization tool that seems to have petered out at 16.x, alas. But the icons have some detail if your theme will show them.
The win-10 notification makes better use of the icon. Older versions of linux had a notification customization tool that seems to have petered out at 16.x, alas. But the icons have some detail if your theme will show them.
Another feature is that the code creates the icon folder if it doesn’t exist. It almost certainly will on Linux but probably won’t on windows unless you’ve run some other Linuxy stuff on your windows box. The directory created on windows is your home directory\.local\share\icons\. On Linux systems, the directory should exist and is ~/.local/share/icons/. In that directory you should copy the default camera icon as “mobotix-cam.ico” like so:

You can put any icon there as your preferred default as long as it is in .ico format, or use the one below (right-click on the image or link and “save as” to download the .ico file with resolution layers):
If, for some reason, the get image routine fails, the code should substitute the above icon so there’s a recognizable visual cue of what the notification is about.
mobotix_notifier.py code
The python code below can be saved as “mobotix_notifier.py” (or anything else you like) and the execution bit set, then it can be run as ./mobotix_notifier.py on Linux or python .\mobotix_notifier.py on Windows. On Linux, the full path to where you’ve installed the command can be set as a startup app and it will run on startup/reboot and just listen in the background. It uses about 13 seconds a day of CPU time on my system.
Click to download the Windows .exe which should download as mobotix_notifier.exe. (14.0MiB) After the above configuration steps of on the camera(s) and firewall are completed it should start silently and run in the background after launch (kill it with task manager if needed) and push desktop alerts as expected. I used “UC” alarms to test rather than waiting for stray cats.
The python code is:
#!/usr/bin/env python3
import requests
from PIL import Image
import socket
from plyer import notification
import io
import os.path
# note windows version needs .ico files
# note windows paths have to be r type to handle
# backslashes in windows paths
# Check operating environment and define path names
# for the message icons accordingly.
# if OS path doesn't exist, then create it.
if os.name == "nt":
Ipath = r"~\.local\share\icons\mobotix-cam.ico"
Epath = r"~\.local\share\icons\mobotix-event.ico"
fIpath = os.path.expanduser(Ipath)
fEpath = os.path.expanduser(Epath)
dirpath = os.path.dirname(fEpath)
if not os.path.exists(dirpath):
os.makedirs(dirpath)
else:
Ipath = "~/.local/share/icons/mobotix-cam.png"
Epath = "~/.local/share/icons/mobotix-event.png"
fIpath = os.path.expanduser(Ipath)
fEpath = os.path.expanduser(Epath)
dirpath = os.path.dirname(fEpath)
if not os.path.exists(dirpath):
os.makedirs(dirpath)
def grab_jpeg_image(camera_ip):
"""Grabs a JPEG image from the specified camera IP."""
# Make a request to the camera IP
response = requests.get(f"http://{camera_ip}/control/event.jpg", stream=True) # noqa
# Check if the request was successful
if response.status_code == 200:
# Convert the response data to an image
image = Image.open(io.BytesIO(response.content))
# Return the image
return image
else:
# import the default icon
image = Image.open(fIpath)
# Return the image
return image
def convert_jpeg_to_png(image, width, height):
"""Converts a JPEG image to a PNG image."""
# size = width, height
# Scale the image
image.thumbnail((width, height), Image.Resampling.LANCZOS)
# Save the image according to OS convention
if os.name == "nt":
icon_sizes = [(16, 16), (32, 32), (48, 48), (64, 64), (128, 128)]
image.save(fEpath, format='ICO', sizes=icon_sizes)
else:
image.save(fEpath)
def iconify(src_ip):
# Grab the JPEG image from the camera
image = grab_jpeg_image(src_ip)
# Convert the JPEG image to a PNG image
convert_jpeg_to_png(image, 256, 256)
def reverse_dns_lookup(src_ip):
try:
return socket.gethostbyaddr(src_ip)[0]
except socket.gaierror:
return "no dns"
except socket.herror:
return "no dns"
def test_str(answer):
try:
return str(answer)
except TypeError:
return answer.to_text()
def listener():
"""Listens for incoming connections on port 8008."""
# Create a socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# Bind the socket to port 8008
sock.bind(("0.0.0.0", 8008))
# Listen for incoming connections
sock.listen(1)
while True:
# Accept an incoming connection
conn, addr = sock.accept()
# Receive the payload of the packet
data = conn.recv(2048)
# Close the connection
conn.close()
# convert from literal string to remove b' prefix of literal string
data = str(data)[2:-1]
# Extract the source IP from the address
src_ip = addr[0]
# Grab the event image as an icon
iconify(src_ip)
# Do a DNS lookup of the source IP
answer = reverse_dns_lookup(src_ip)
# Get the hostname from the DNS response
hostname = test_str(answer)
# Write the hostname to notify-send
title = (f"Event from: {hostname} - {src_ip}")
message = (f"{data} http://{src_ip}/control/userimage.html")
notification.notify(
title=title,
message=message,
app_icon=fEpath,
timeout=30,
toast=False)
# Echo the data to stdout for debug
# print(f"Event from {hostname} | {src_ip} {data}")
if __name__ == "__main__":
listener()
Please note the usual terms of use.
The end of a comic era
Tonight I listened to the last episode of NPRs excellent and hilarious Ask Me Another, though originally broadcast on 2021-09-24, it didn’t reach my ears until tonight thanks to the magic of podcasts. It was genuinely hard to hear them sign off for the last time. I will really miss this show and the warmth and good spirits of Ophira Eisenberg and Jonathan Coulton.
I’ve been listening to this show since it started, back so far as to have been over syndicated FM broadcast on KQED at home and since on various digital media over the years wherever I’ve been, even here in Iraq. It suffered when Covid hit, the energy and charm didn’t translate well to zoom and without an audience as so many things didn’t and sadly didn’t live to see Covid restrictions lifted. It would have been fitting if they’d been able to record their last show at The Bell House one more time. Maybe someday they can have a reunion show.
US Public Radio has been an anchor of good quality programming, from Car Talk, which I still listen to weekly despite the questions being increasingly out of touch (though the cars have long been fairly irrelevant) and Fresh Air and Terry Gross‘ voice, which came from my mother’s kitchen radio every afternoon from WHYY about as far back as I can remember.
